Self-supervised learning and its applications to speech processing(李宏毅教授短講)
這是我第二次參加人工智慧年會,今年終於有李宏毅老師的短講了。就在這邊type一些議程筆記。
題目是: Self-supervised learning and its applications to speech processing

自監督式學習有BERT和SimCLR兩個較廣為人知的演算法框架。
BERT是在文字上的應用; 而SimCLR是在影像上的應用。
那在Speech上呢? 又有甚麼基於自監督式學習的技術應用呢?在語音上的表現又是如何?

Self-supervised learning有兩個Phase(階段)的訓練:第一個Phase式Unlabeled Data training 也就是沒有給標籤的訓練。這個模型訓練好後,我們就稱它為上游模型(Upstream Model)。這個上游的模型在做的事就是: 輸入一段聲音訊號,輸出一段向量的representations。
那你可能會很好奇說,阿這些沒標註的資料是用甚麼方法訓練出上游模型的勒?在沒有標註的情況下,是怎麼被訓練出來的? 這次不會細講,下圖Po出一些方法。
- Mask the input signals and then reconstruct them.
- Predict the targets obtained without human efforts.
- Contrastive learning.
(Contrastive learning is a machine learning technique used to learn the general features of a dataset without labels by teaching the model which data points are similar or different. Let’s begin with a simplistic example. Imagine that you are a newborn baby that is trying to make sense of the world.)
但雖然我們用這些方法訓練出上游模型,但我們卻在此時此刻不知道上游模型會怎麼樣拿來被使用,這個狀態稱為"Taks-agnostic”.
所以目前有:下圖這些上游模型,在語音的任務上。可以把它們想像成是語音版的BERT.


Phase2 第二階段的訓練:
加入下游模型,由上圖可看到,這個階段會加入一些有標籤的資料用來訓練下游模型。而有時候這些被標籤過的資料也能拿來微調上游模型。(用虛線表示不是一定必要的任務)。

現在那麼多上游模型,但現在想問一個問題…他們到底是語音任務上的"專才還是通才呢?"。
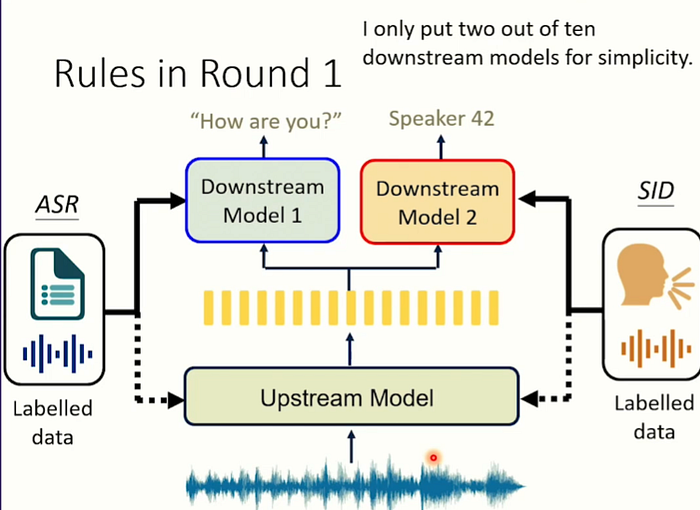
同樣一個上游模型,它在語音辨識上做起來的結果好,但在語者辨識上也會好嗎?

若在一年前,宏毅老師覺得他們是專才並非通才。但這只是一個猜想…
所以老師就跟其他世界級的研究單位一起研究這個問題,"同一個上游模型的pre-train model 有沒有可能變成通才? 任何關於語音的任務都有可能train得好?"。以下是這個計劃的名字"SUPERB"。


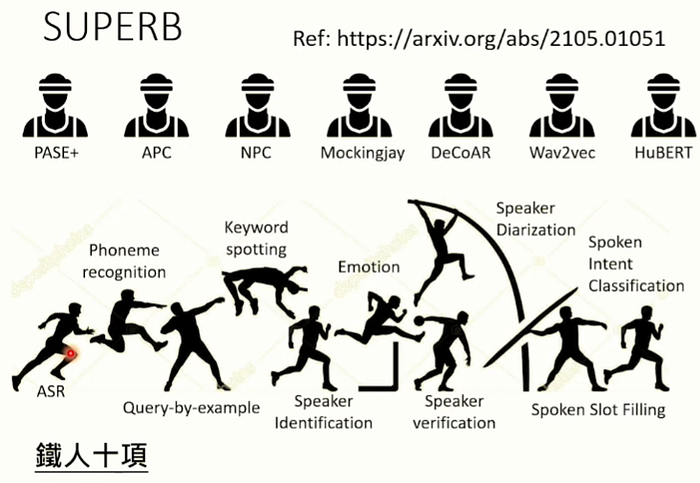
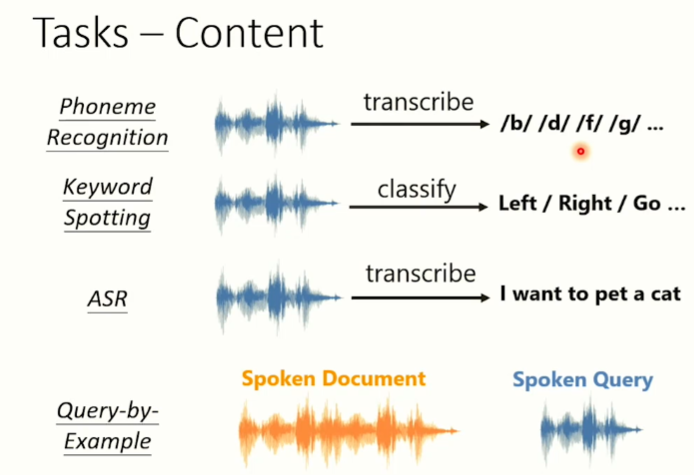
讓這些模型(運動員)做語音任務上的"鐵人十項"。以下是語音的其中4個Content的任務。
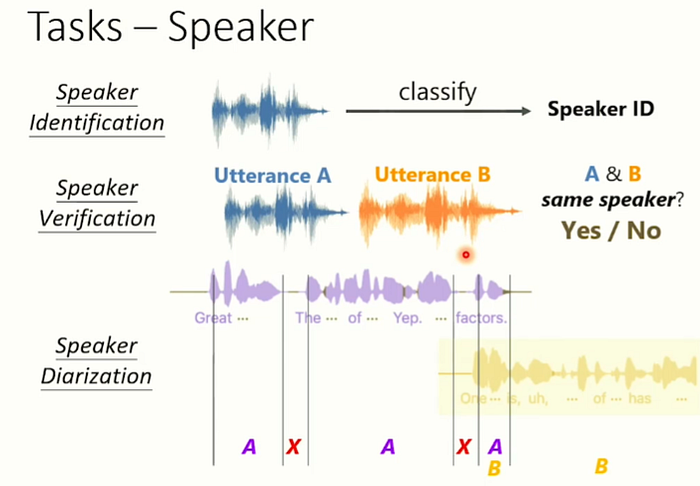
以下是語音的其中4個語者(speaker)的任務。
以下是語義的任務。(通常是先轉成文字再轉成語音)但在這邊會直接做一個End to End的模型,直接不用通過轉成文字就完成語義理解。輸入一段聲音訊號,輸出一段機器人理解的內容。(NLU content)
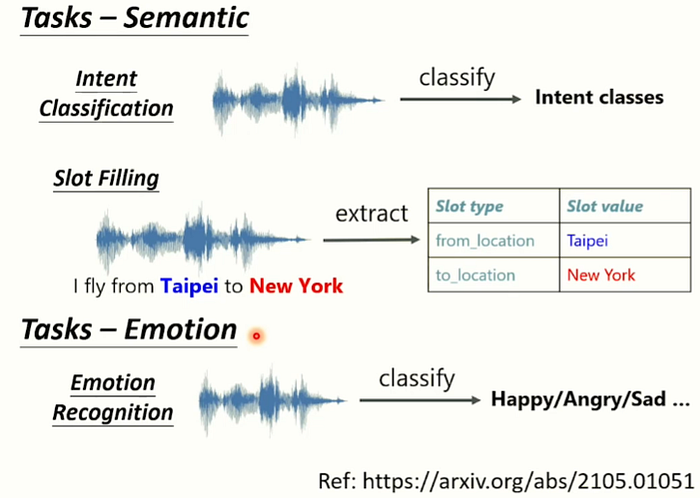
那我們現在都設定, 也了解了比賽的項目和規則,那就即刻讓運動員們(upstream models)開始進行比賽吧!

第一回合比賽:
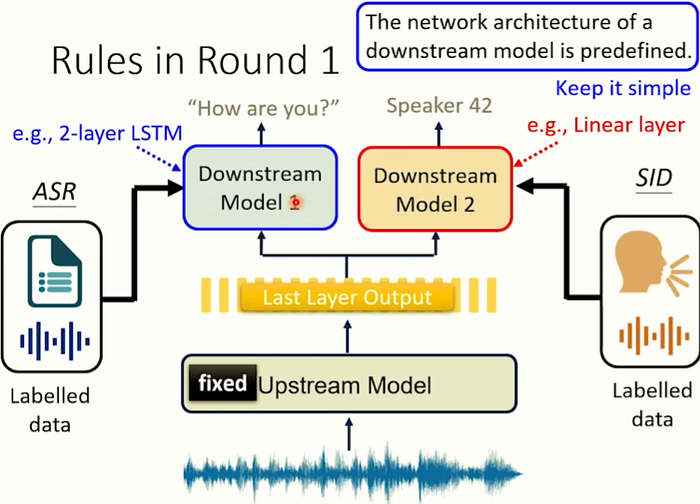
我們一開始就給上游模型一個限制,限制內容是"上游模行不能更動內部參數"然後最後我們只取上游模型最後一層的輸出; 當作下游模型第一層的輸入。然後這個下游模型我們希望越簡單越好…在這邊,下游模型只用一個linear layer。 那為什麼要給出這些限制呢?
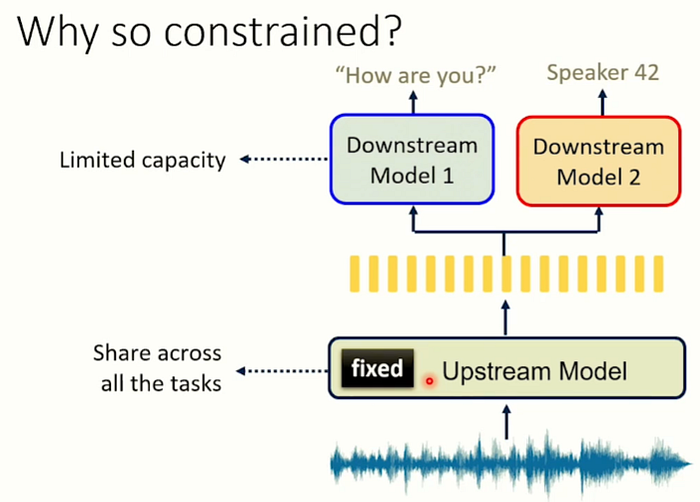
因為我們想知道給他們手腳綁住鉛塊,能不能夠也跑得起來,若連這樣都train得起來,那可想而知解掉限制後能夠加快。
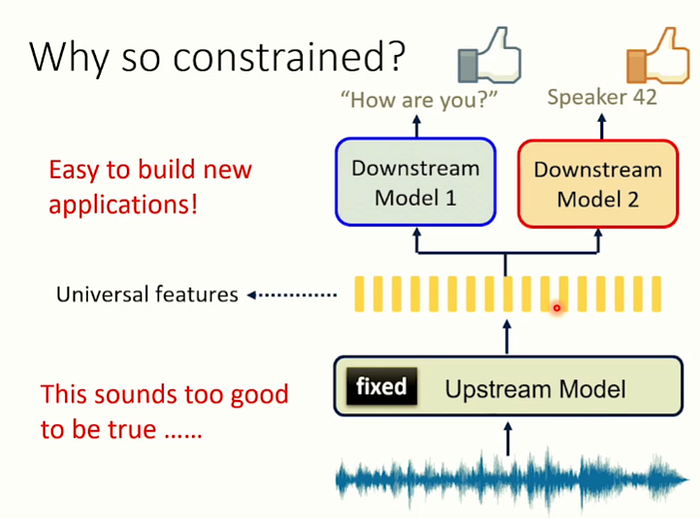
假如我們可以在一個上游模型中找到一組Universal的features並且讓所有語音的任務都可以執行的好是一件多美好的事情? 但真的有可能嗎?或許太過理想… 但沒關係,就先做實驗再說!
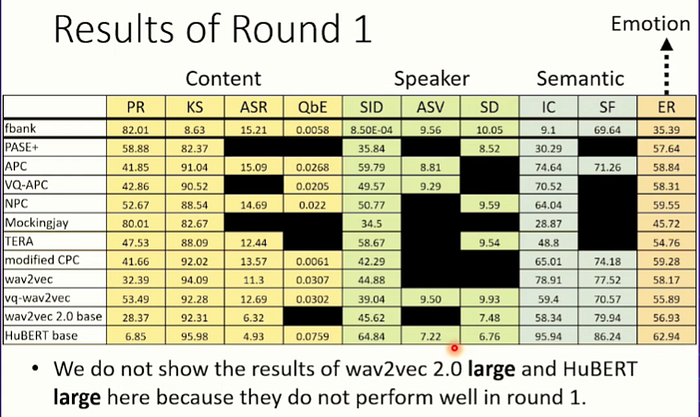
以上是做完實驗後做的一個模型表現的表格。以fbank模型做baseline,為甚麼呢? 因為fbank是沒有做自監督式學習的,所以跟其他都有做自監督式學習的models來比就可以看出自監督式學習到底有沒有效過。
被塗黑的部分代表它的表現沒有比fbank來的好,換句話說就是自監督式學習對它在某些任務下是沒有用的。但值得慶幸的是,表格上塗黑的部分並沒有很多,代表說自督導式學習對於語音任務的model來說幾乎都是有效果的。除了語者任務(Speaker)可能比較沒效果…
那接下來想進行第二回合的比賽:
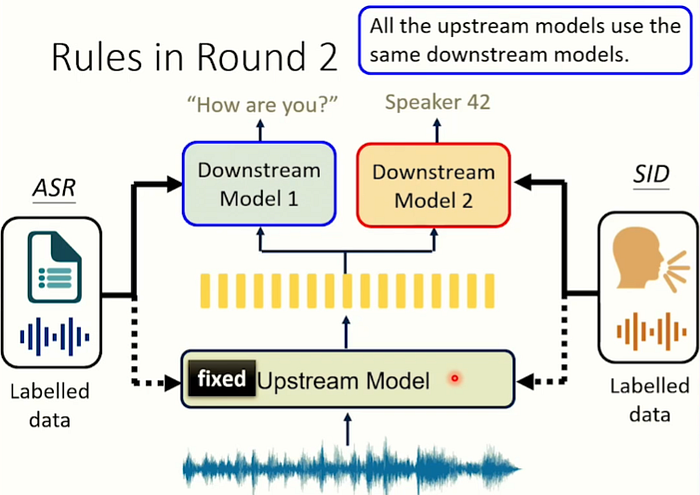
第二回合幾乎process都一樣,不一樣的是我們不再只用上游模型最後一層的輸出當作下游模型的輸入。我們讓下游模型選擇他們自己想要的那一層輸出,而不是只用固定的最後一層。
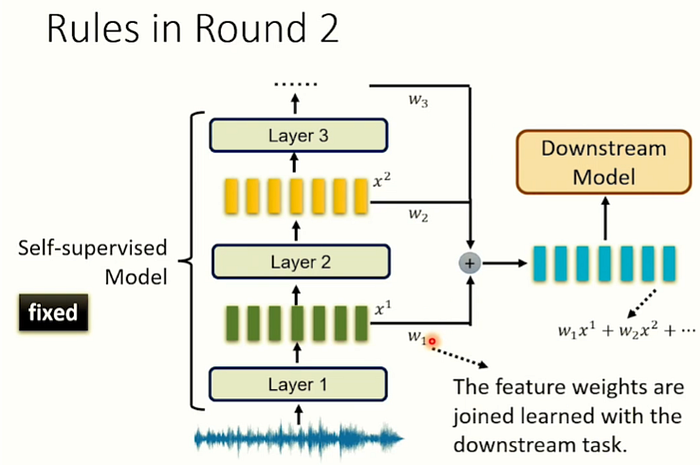
那該怎麼做呢? 方法是這樣: 上游模型每一層的輸出都會是一堆向量,接下來我們把這些向量做加權平均,得到新的向量,新的特徵值。而這些權重是跟下游模型一起訓練出來的。所以…不同的任務, 不同的下游模型, 就可以選擇不同的權重。這就是剛剛說的: 一個上游模型或許非常大有3 4十層layer,到底哪一層是適合哪一個任務的呢? 我們不知道,所以讓下游模型自己透過訓練去選。讓下游模型自己決定它想要用哪一層的輸出,來解它現在想要解的問題。
接下來就是第二回合比賽的結果表格:

可以看到塗黑的地方變少了,可見第二回合的策略讓自監督式學習的效果更拔群了,甚至有些模型真的做到了"十項全能":NPC、DeCoAR2.0、wav2vec、etc…等七個模型。

所以一年後的現在宏毅老師會說,它們可以是通才!但是…

那接下來你可能會問: 那這件事是怎麼得到的呢?為甚麼這些模型在不一樣的任務當中都能夠得到好的結果呢?
老師的回答是: 目前還不曉得,我們只知道他們可以做到十項全能,但細節的黑盒子還尚待團隊去一一解開…請持續追蹤!

如果您對自己的模型有信心的話歡迎來打上圖網站的這個leaderboard.
這次的議程筆記就先到這兒。歡迎轉載或交流~但我希望可以先跟我打個招呼:) 感謝 感謝。
那我們下回見! I’m kevin, See you.
